
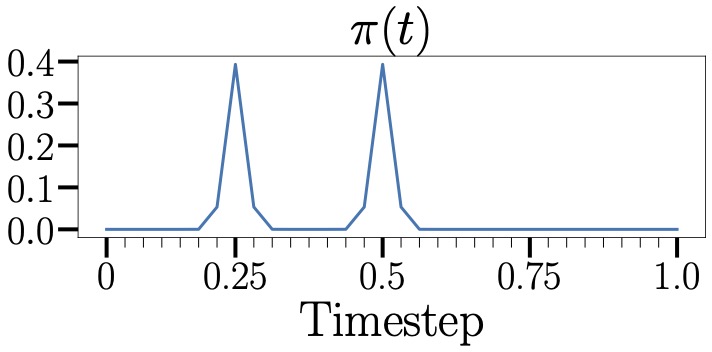
Warm-up
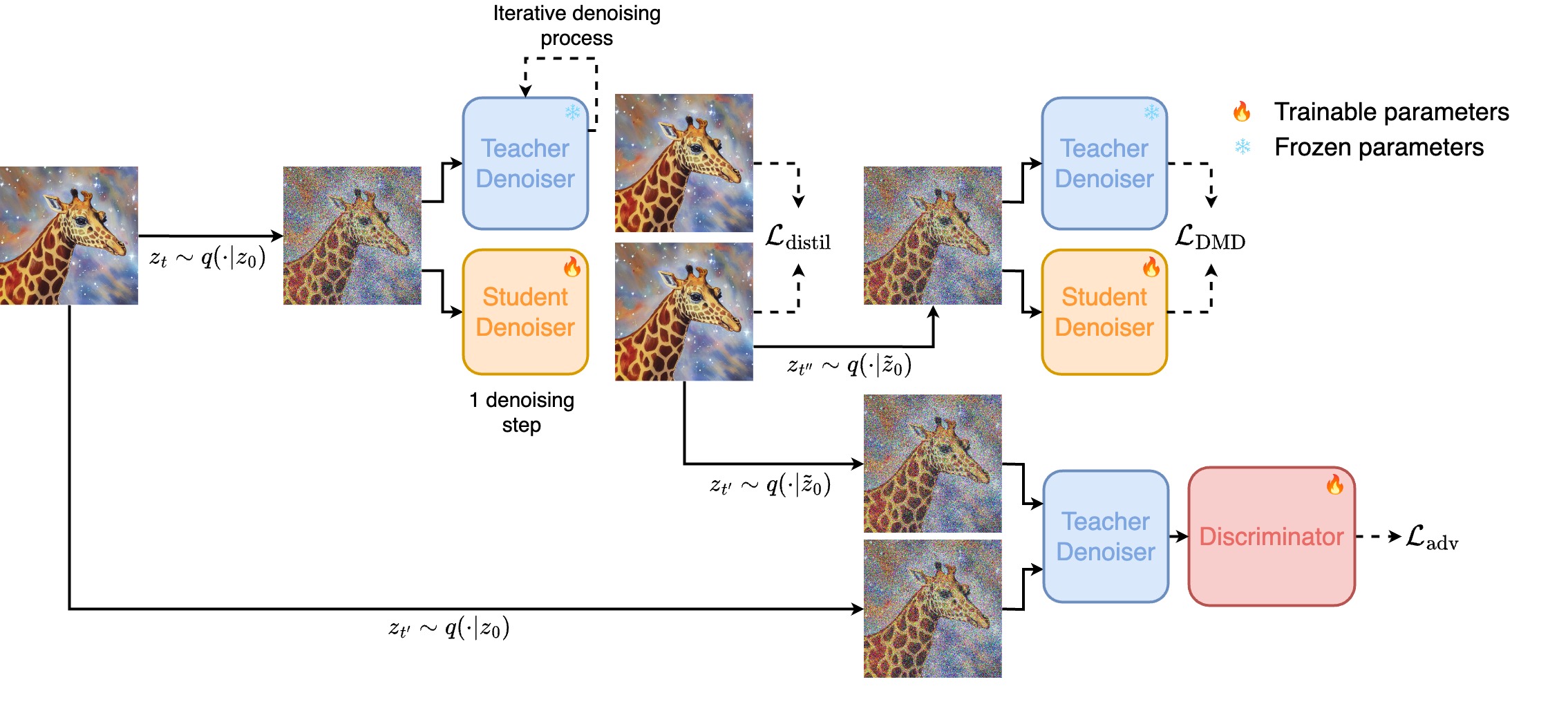
Fig 1: Flash Diffusion training method diagram
Our method aims to create a fast, reliable, and adaptable approach for various uses. The proposed method aims at training a student model to predict in a single step a denoised multiple-step teacher prediction of a corrupted input sample. Additionally, we sample timesteps from an adaptable distribution that shifts during training to help the student model target specific timesteps.
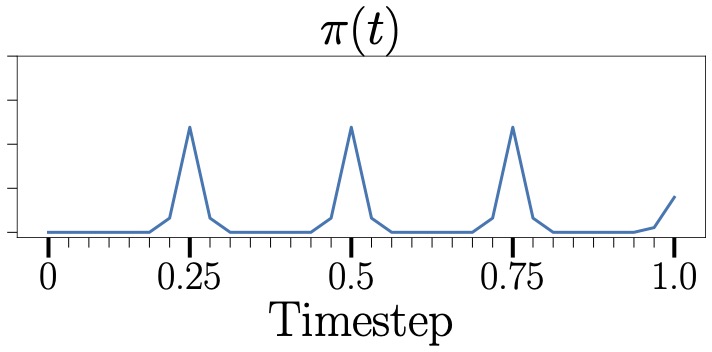
Warm-up
Phase 1
Phase 2
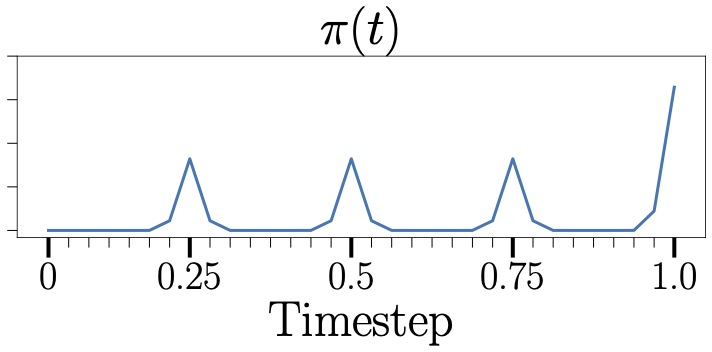
Phase 3
To further enhance the quality of the samples and since it proved very efficient in several works, we have also decided to incorporate an adversarial objective to train the student model to generate samples that are indistinguishable from the true data distribution. Therefore, we trained a discriminator to distinguish the generated samples from the real samples and apply it within the latent space to lower the computation requirements.
Finally, we also used a Distribution Matching Distillation Loss to ensure that the generated samples closely mirror the data distribution learned by the teacher model.
We also illustrate the ability of the proposed method to adapt to different backbones and trained using both UNet-based architecture and DiT models. Here are the results for FlashSDXL and FlashPixart


Our method can be used to train models for various use cases such as Inpainting, Upscaling, Face-Swapping and many more. Here are a couple of examples :



@misc{chadebec2024flash,
title={Flash Diffusion: Accelerating Any Conditional Diffusion Model for Few Steps Image Generation},
author={Clement Chadebec and Onur Tasar and Eyal Benaroche and Benjamin Aubin},
year={2024},
eprint={2406.02347},
archivePrefix={arXiv},
primaryClass={cs.CV}
}